
Série: IA na gestão do conhecimento - parte 4
Fechamos a série mostrando duas maneiras de interagirmos com nossos documentos usando um LLM e por quê os Knowledge Graphs são tão poderosos.
Nicholas Arand
5/7/20245 min read


Ao longo de nossa série sobre o uso da Inteligência Artificial (IA) na gestão do conhecimento, já exploramos como os Modelos de Linguagem (LLMs) podem ser utilizados para estruturar conhecimentos dispersos em documentos montando Gráficos de Conhecimento. Através de um exemplo prático simples, usando currículos e descrições de cargo, demonstramos também a possibilidade de encontrar conexões entre conhecimentos anteriormente dispersos, permitindo identificar, por exemplo, o candidato ideal para uma vaga. Hoje, avançaremos ao ver como podemos, novamente, usar um LLM para interagir com nossos gráfico usando duas abordagens distintas, o RAG tradicional e o RAG enriquecido pelo Gráfico de Conhecimento que construímos.
O RAG, ou Retrieval-Augmented Generation, representa uma técnica avançada para fornecer ao modelo informações específicas necessárias para uma consulta. Lembre-se que os modelos de linguagem foram treinados com muita informação, mas não necessariamente a informação que precisamos dentro de nosso trabalho ou, especificamente, nosso conhecimento corporativo. Sendo capaz de incorporar dados proprietários durante o processo de interação com o modelo de linguagem, esta abordagem visa suplementar o conhecimento intrínseco do model, mitigando as chamadas "alucinações" – momentos em que o modelo gera informações imprecisas ou completamente fictícias para nos fornecer uma resposta. Ao vincular diretamente a fontes de informação verificáveis, o RAG fortalece a qualidade e a credibilidade das respostas geradas pelos LLMs.
Apesar de promissor, o RAG tradicional não é infalível. Ao depender da qualidade e da relevância dos dados consultados, a eficácia dessa técnica é limitada pela solidez da informação encontrada nos documentos. Ou seja, embora reduza significativamente o risco de alucinações, o RAG tradicional permanece suscetível a à forma como o conhecimento é disponibilizado, podendo ocasionalmente resultar também em geração de informações inexatas. Em nosso exemplos simples, vemos que a informação sobre os candidatos e a informação sobre as vagas estão separadas em documentos distintos. Para que um modelos de linguagem consiga estabelecer relações entre estas informações, ele precisaria ser capaz de entender o que queremos, encontrar os documentos necessários e estabelecer as relações entre as informações, tudo isso apenas confiando em sua capacidade de sequenciar palavras probabilisticamente. É exigir demais da ferramenta, mas podemos tentar.
Perguntando aos nossos documentos “Qual o melhor candidato para a vaga de Engenheiro de Qualidade?”, e fazendo um RAG que busque as informações de todos os CVs (para considerar todos os candidatos) e a descrição de cargo que faz o melhor “match” com a pergunta temos a seguinte resposta:
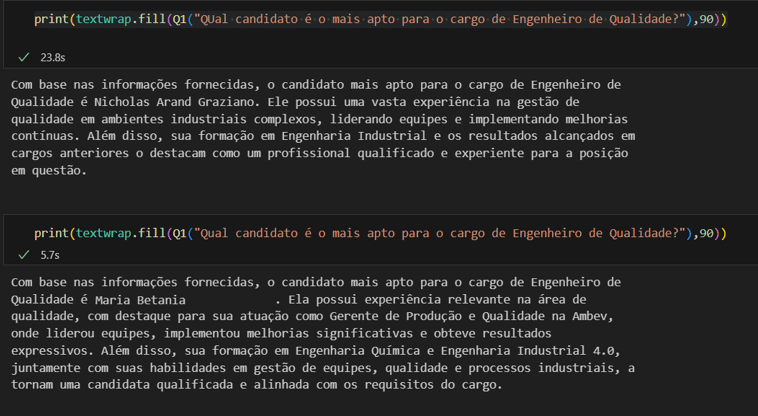
Notem que fiz a mesma exata pergunta duas vezes e obtive duas respostas bastante diferentes. Ambas com justificativas convincentes, apesar de o modelo ter acrescido um sobrenome aleatório a mais em meu nome, mas definitivamente muito diferentes.
Por que isso ocorre? Isso é um exemplo claro de “alucinação” do modelo. Exigimos um esforço “cognitivo” maior do que um modelo sequenciador de palavras é capaz de produzir com consistência e o modelo entregou exatamente o que ele é projetado para entregar… uma sequência válida de palavras, mas não suficientemente embasada em fatos como necessitamos na indústria.
Veremos agora que a integração do RAG com Gráficos de Conhecimento eleva radicalmente a precisão e a contextualização da informação. Ao utilizar um grafo construído com currículos e descrições de cargos, essa abordagem não apenas fornece ao LLM acesso a informações detalhadas e concretas, mas também realça as conexões entre elementos que não se encontram em um mesmo documento, enriquecendo a análise e a interpretação do modelo. Essa combinação permite não só um maior alinhamento entre as demandas da empresa e os perfis dos candidatos, mas também uma compreensão mais profunda das dinâmicas e lacunas de habilidades dentro da organização.
Voltemos ao grafo criando ao longo dos posts anteriores.
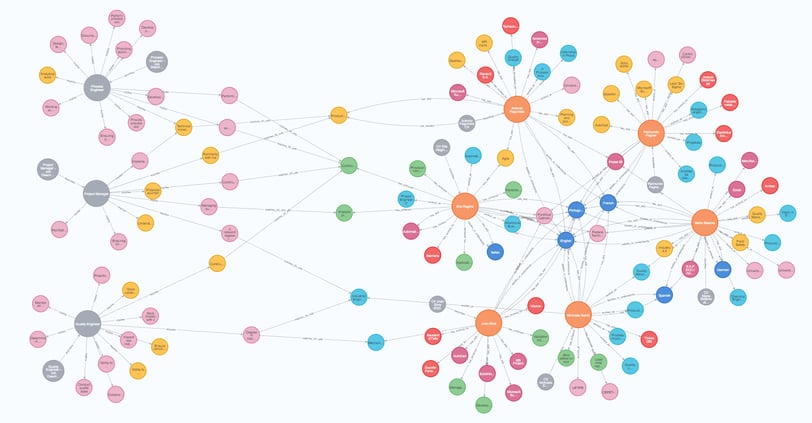
Lembrando que os candidatos estão representados pelos círculos alaranjados maiores (6 candidatos) com suas habilidades e experiências orbitando ao seu redor, As descrições de cargo (3 descrições) são representadas com os círculos cinza maiores, com seus requisitos também ao seu redor. Já fizemos também, no post passado, a ligação entre os requisitos e as habilidades usando a capacidade de interpretação semântica do GPT 4, portanto o grafo já faz as ligações entre as diferentes informações.
O que precisamos fazer agora é criar uma cadeia de consulta que envolve um query em nossa base gráfica. E, pasmem, acontece que o GPT4 também é bastante bom em transcrever nossa linguagem natural em linguagens de programação como o cypher, utilizado em nossa base gráfica. Passando para o LLM o esquema e as regras de nossa base de dados, ele pode criar consultas que buscam a informação necessária para responder às perguntas que fizermos. O query é usado então para gerar os dados que serão utilizados para responder às questões colocadas ao modelo.
Na figuras abaixo mostro uma pergunta qualquer, a consulta que o LLM elaborou para poder responder a cada pergunta, a resposta da base de dados e, finalmente, a resposta dada pelo modelo. Notem o nível de precisão que conseguimos.
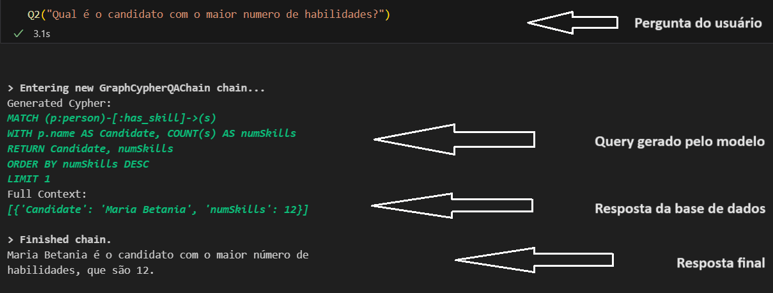
Vamos agora tentar responder à mesma pergunta que fizemos usando o RAG tradinional:
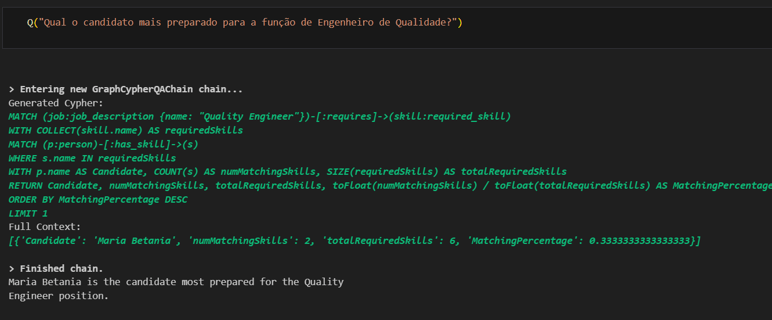
Note que a resposta final bate com uma das respostas dadas anteriormente, mas aqui temos a vantagem de saber que a Maria Betania foi escolhida por suas habilidades que casam e 33% com as habilidades demandadas para o cargo. Podemos ainda perguntar quais são elas:
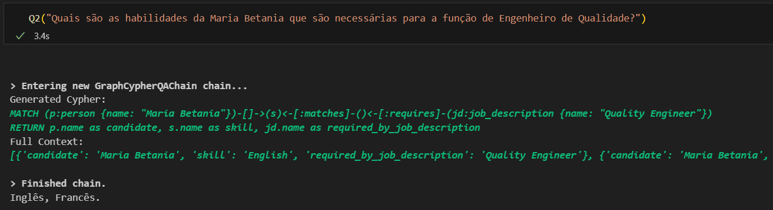
E de forma semelhante, podemos desenvolver perguntas bem diferentes:
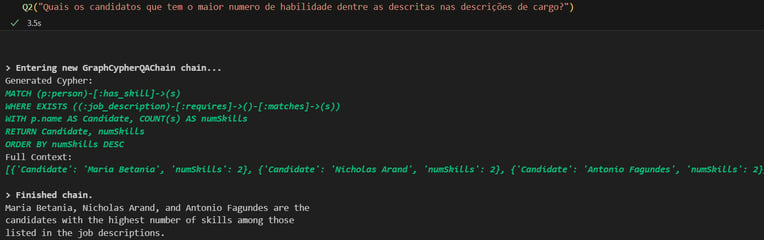
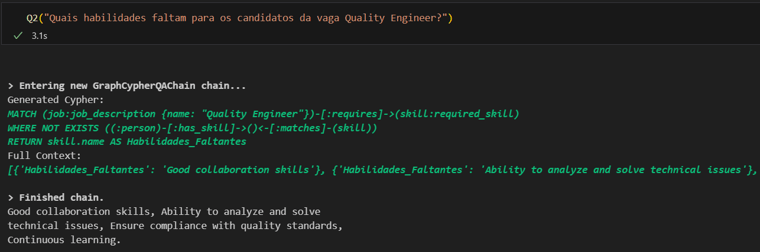
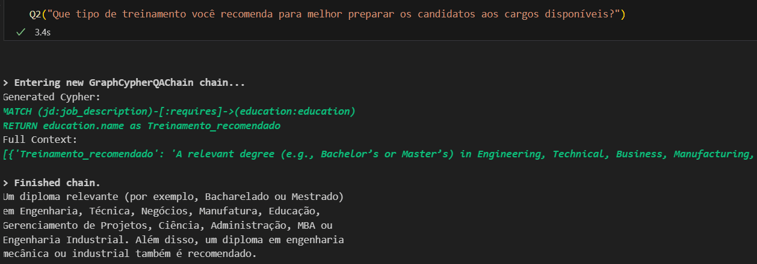
Ao concluir nossa discussão sobre a aplicação de LLMs na gestão do conhecimento, fica evidente o potencial revolucionário das técnicas de RAG, especialmente quando complementadas por Gráficos de Conhecimento. Essas estratégias oferecem caminhos promissores para superar desafios de conhecimento disperso, facilitando uma tomada de decisão mais informadas nas organizações. De novo, o exemplo usado foi bastante simplório e simbólico, usando CVs e JDs em pequena quantidade. Mas espero ter deixado claro que a aplicação pode facilmente ser escalada para bases de conhecimento muito grandes e mais complexas.
Você consegue pensar em algum exemplo aí na sua empresa, onde dados e informações dispersas em vários tipos de documentos podem ser úteis para você quando organizados desta forma?
Lembrando que todos os códigos usados nesta série estão disponíveis em meu github: https://github.com/nikinuk/KnowledgeGraphsDemo