
Série: IA na gestão do conhecimento - parte 3
No terceiro post da série, ampliamos nossa base com descrições de cargo e revelamos os poderes da integração de diferentes documentos com as LLMs
Nicholas Arand
4/29/20244 min read
A cada pequeno passo que damos nesta série adicionamos um pouco de complexidade mas, vamos também, chegando cada vez mais próximo dos resultados incríveis que podemos conseguir usando as ferramentas de IA generativa. No primeiro e segundo post, mostrei como podemos utilizar um modelo de linguagem para extrair informações de documentos na forma de entidades e relações entre entidades, a fim de estruturar conhecimento desestruturado. Inicialmente, retiramos nomes, experiências de trabalho, habilidades de apenas um CV e, logo, repetimos a operação para um punhado de currículos ao mesmo tempo, criando uma base de dados com, por exemplo, candidatos a uma vaga, identificando suas habilidades comuns e especiais (figura). Neste terceiro post vamos acrescentar mais informações à nossa base de conhecimento, algumas descrições de cargo, incluindo assim, os requisitos de vagas abertas.
A verdade é que não é nada difícil extrair informações de um CV e comparar as habilidades de cada candidato às necessidades dos cargos. Mas e se temos, como hoje é muito comum, centenas de currículos para dezenas de vagas? Vimos que com a ajuda de um modelo de linguagem extraímos dados de 6 CVs em apenas 2 minutos, a um custo de apenas 10 centavos. E com todos os CVs em nossa base podemos facilmente comparar candidatos e visualizar suas habilidades comuns e as que os diferenciam.
Agora, neste terceiro post vamos ampliar nossa base de conhecimento com três descrições de cargo para vermos um exemplo de como podemos ganhar insights com mais informações na base. Lembrem que a escolha de usar CVs e Descrições de Cargo é absolutamente arbitrária. Poderíamos estar fazendo aqui a mesma análise com procedimentos e normas, relatórios de não conformidade e planos de ações corretivas, chamadas de manutenção e manuais técnicos e assim por diante. O objetivo é demonstrar o que a capacidade de compreensão semântica das LLMs pode fazer com dados não estruturados como documentos, e-mails, mensagens, etc.
Imagine as descrições de cargo como documentos onde a empresa contratante define as funções, responsabilidades e requisitos mínimos para que as funções dentro da organização sejam exercidas. Da mesma forma que fizemos para os CVs, o primeiro passo é definir uma ontologia, ou seja, quais as entidades e relações entre entidades que vamos extrair deste documento. Para exemplificar o caso, definimos a seguinte regra:
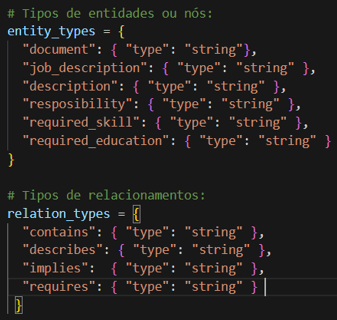
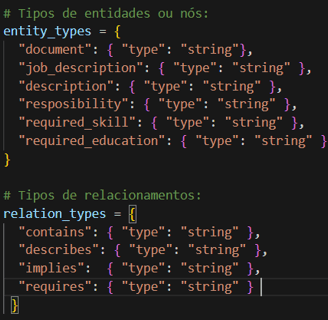
Com a ontologia definida, precisamos apenas fazer algumas pequenas adaptações no prompt que utilizamos para a extração de dados dos CVs e conseguiremos os mesmos resultados. Após realizar o mesmo tipo de operação de resolução de ambiguidades que fizemos para os CVs e criar os novos nós e relacionamentos na base, o resultado pode ser visto a seguir.
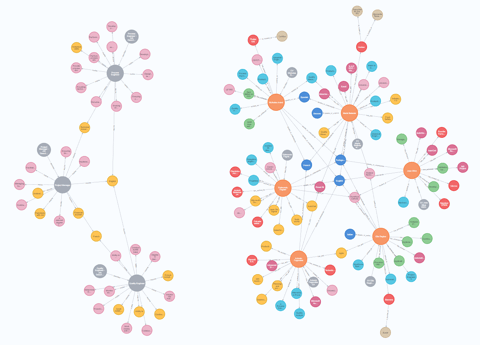
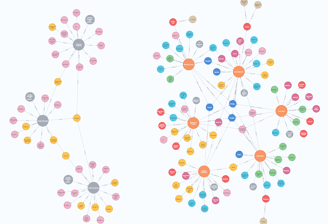
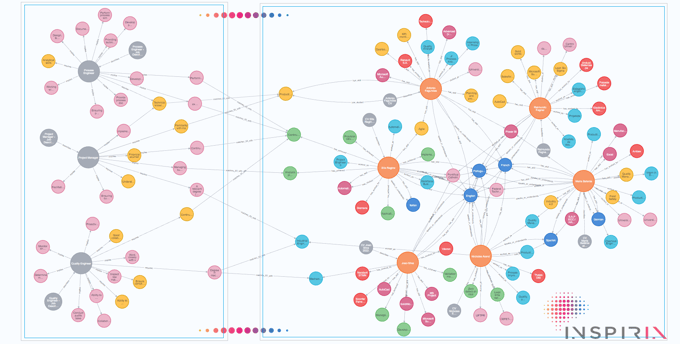
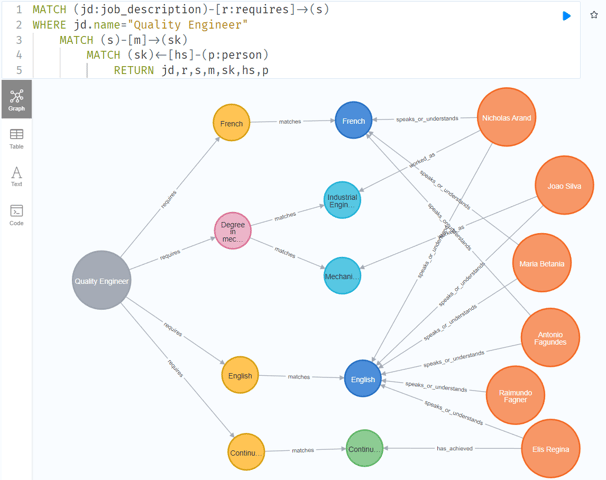
Note que podemos ver os requisitos e responsabilidades exclusivos de cada vaga bem como os tópicos que elas têm em comum. O que também podemos notar é que nossas representações gráficas das descrições de cargo e dos candidatos às vagas não se conectam... ainda.
O problema que enfrentamos neste momento é que, até podemos tentar controlar o vocabulário e jargões que queremos utilizar nas descrições de cargo da empresa forçando uma certa padronização, mas a linguagem dos CVs está completamente fora de nosso controle. Temos, no nosso exemplo, não apenas CVs submetidos por diferentes candidatos, com seu próprios estilos de escrita, mas também, alguns CVs em inglês e outros em português. Para fazer uma comparação automática entre estas diferentes entidades precisamos, novamente, da ajuda dos modelos de linguagem. A beleza dos LLMs é que eles traduzem a semântica da linguagem natural para uma linguagem matemática que, de certa forma, independe de idiomas e jargões utilizados. Utilizando um LLM, no caso, ainda o GPT4, podemos comparar bananas com bananas, ou maçãs com pommes e apples, e até o requisito “A relevant degree (e.g., Bachelor’s or Master’s) in Engineering, Technical, Business, Manufacturing, Education, Project Management, Science, Management, MBA, or Industrial Engineering” com a habilidade “Industrial Engineer”.
Fazendo este exercício com mais uma chamada do API da OpenAI, através do próprio banco de dados, temos o seguinte gráfico mostrando como tudo o que temos se relaciona.
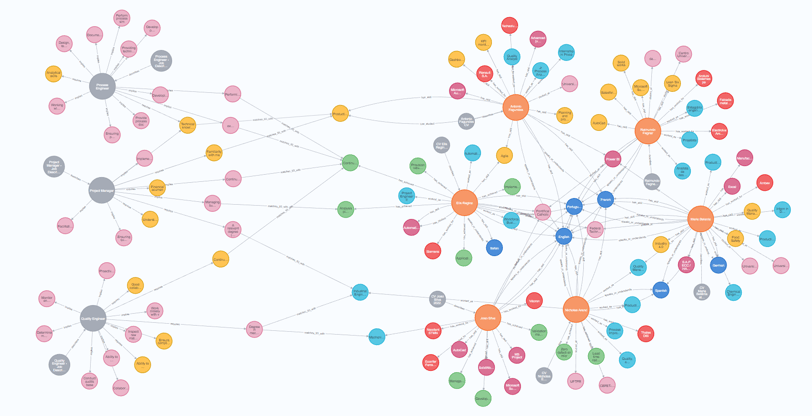
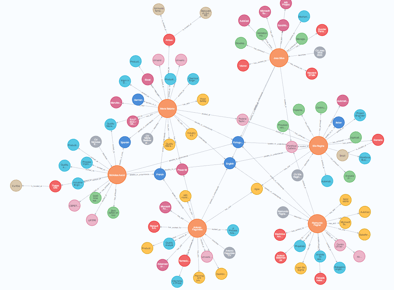
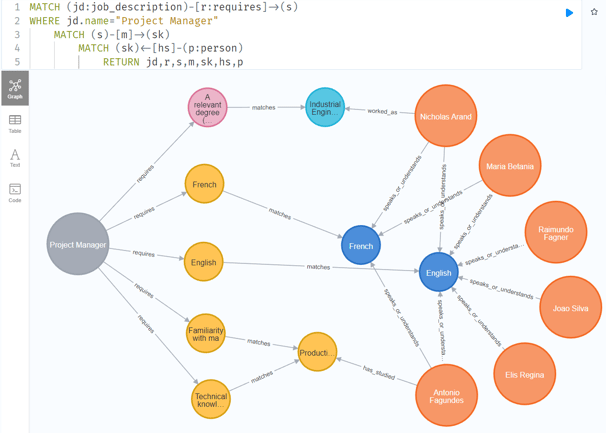
Com a consulta e filtros corretos, podemos facilmente ver que, por exemplo, para o cargo de “Project Manager”, o candidato Antonio Fagundes é o que mais possui habilidades que casam com os requisitos.
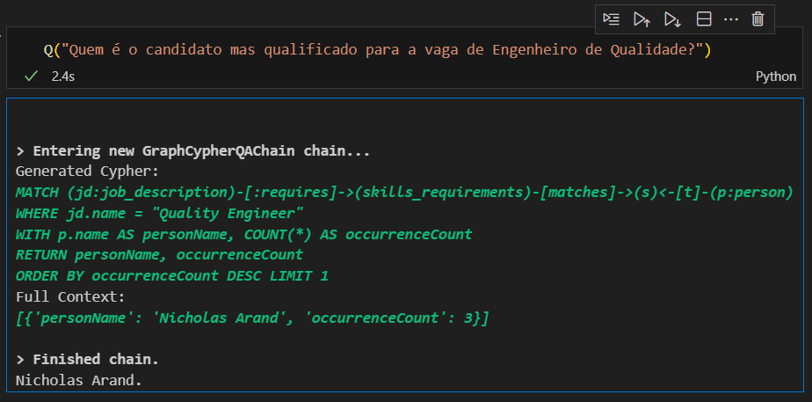
No próximo post, agora sim, vou mostrar que, ou invés de termos que interagir com nossa base de dados fazendo consultas ou cutucando os gráficos, podemos também interagir com a nossa base usando um LLM. Prévia para os curiosos:
O candidatos, representados pelos círculos laranja, rodeados por seus principais atributos. Note que habilidades comuns a mais de um candidato aparecem os conectando ao centro da imagem.
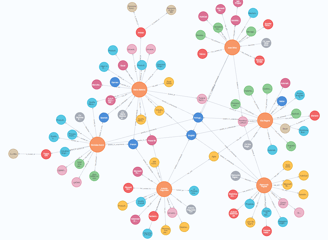
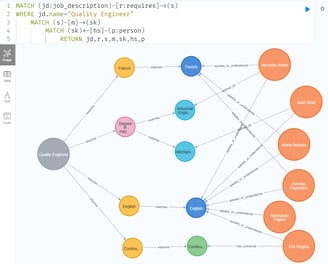
Ou fazendo a mesma consulta para outra descrição de cargo:
Para quem se interessar, o notebook completo usado nesta demonstração está no meu github: https://github.com/nikinuk/KnowledgeGraphsDemo como "publication III.ipynb"