
Série: IA na gestão do conhecimento - parte 2
No segundo post da série, mergulho um pouco mais no caso apresentado de estruturação de dados de CVs
Nicholas Arand
4/24/20244 min read
Neste segundo post da série, vamos ampliar um pouco a experiência que fizemos no post anterior, quando estruturamos os dados do meu CV usando o GPT3.5-turbo, mas incluindo, agora, diversos CVs. A idéia é demonstrarmos rapidamente as vantagens de termos os dados estruturados e, também, as vantagens de fazermos isto usando os modelos de linguagem (adiantando, custo e velocidade).
Suponha que você trabalha no RH e está realizando um processo de seleção para um cargo de engenheiro. A empresa onde você trabalha é certamente um excelente lugar para trabalhar e, portanto, você recebe muitos CVs nos mais variados formatos e de pessoas com as mais variadas experiências e características. Como você faz para selecionar os melhores curriculos? Note que cada aplicante enviou o CV em um formato e layout diferente, como sempre fazemos, portanto não é fácil fazer uma comparação rápida:
Se você tem tempo e paciência, vai, certamente, ler um por um e fazer uma triagem inicial baseado nas experiências relatadas e nas habilidades listadas por cada aplicante, versus os requisitos da vaga. Um trabalho árduo que exige cuidado e a capacidade de encontrar, nas entranhas dos textos e quadros, os conceitos-chave que definem e determinam as habilidades necessárias para a função. Mas se você tem acesso ao assistente de IA que construímos no primeiro post da série, pode fazer isso automaticamente. Atualizei o script usado para analizar o meu CV para que analize, um por um, totos os CVs que tenho quardados em uma pasta. Não é instantâneo nem de graça, mas em apenas 2 minutos meu assistente processou 6 CVs:




Note que o assitente levou cerca de 20 segundos para processar cada CV, consumindo entre 3200 e 4200 tokens do GPT3.5, que a valores atuais corresponde a U$D 0,0033 por CV. Custo total de 2 centavos de dolar, ou 10 centavos de real.
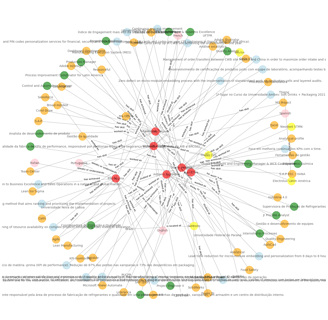
O que temos agora? Temos uma grande tabela contendo nome de aplicantes, suas conquistas, suas habilidades declaradas, locais onde trabalharam, idiomas que dominam, enfim, informações discretas conforme ontologia que criamos na etapa (post) anterior. Mas antes de podermos comparar os aplicantes precisamos passar a base pelo processo de "Entity Resolution", que consiste resolver possíveis ambiguidades não detectadas na extração do conhecimento.
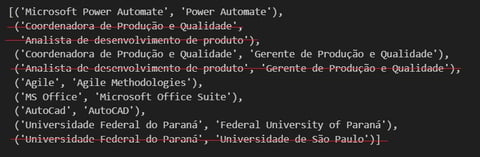
Note que alguns curriculos foram enviados em portugês, outros em inglês. Como fazemos, então, para, por exemplo, garantir que nossa base de conhecimento sabe que, usando um exemplo real deste exercício, 'Universidade Federal do Paraná' e 'Federal University of Paraná', é a mesmíssima coisa? Precisamos fazer uma comparação semântica dos termos usados e padronizá-los de alguma forma. A técnica para fazer isso é um pouco arbitrária, eu usei um modelo aberto chamado 'all-MiniLM-L6-v2' que me resolve o problema rapidamente e sem custo. Como resultado identifiquei algumas ambiguidades reais, outras nem tanto. Resolvi as que não estão riscadas substituindo os um dos termos pelo outro equivalente em toda a base.

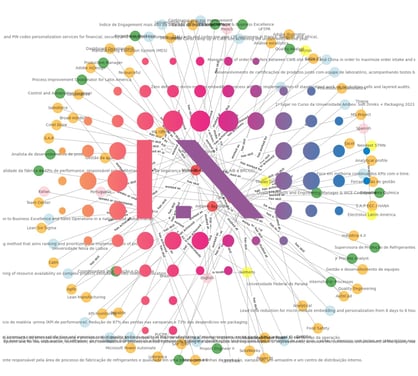
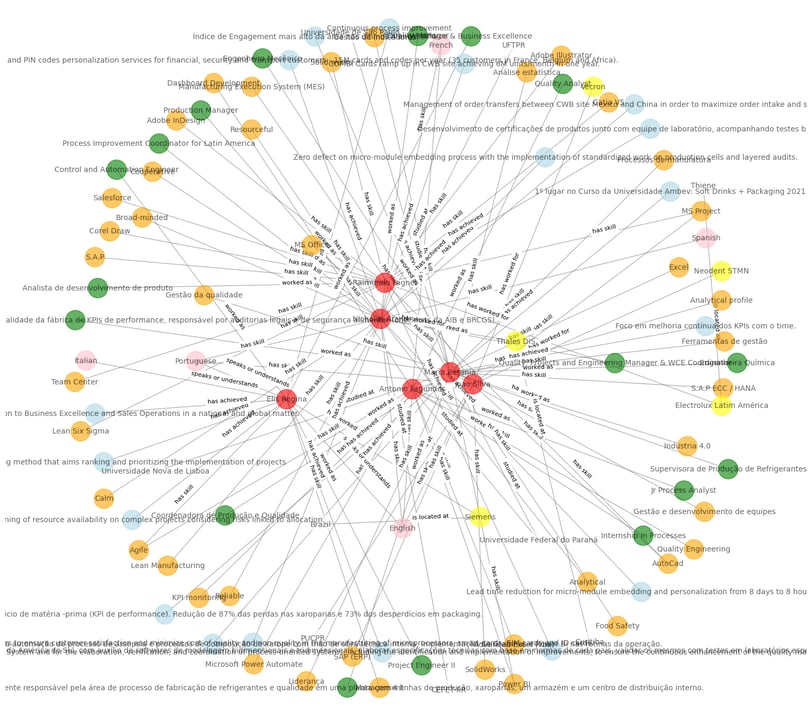
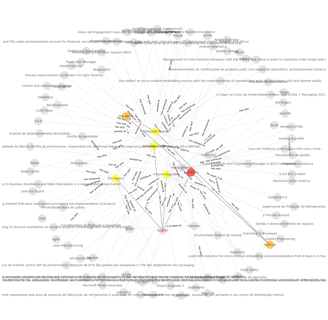
Resolvidas as ambiguidades podemos ver agora o nosso gráfico de conhecimento com todos os aplicantes e suas habilidades, conquistas, idiomas, etc. Usei diferentes cores para ilustrar os diferentes tipos de entidades apenas para facilitar a visualização.
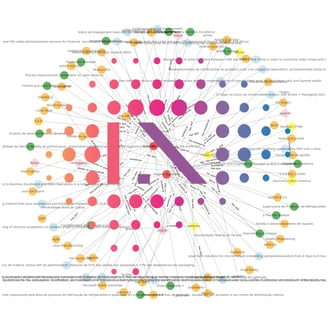
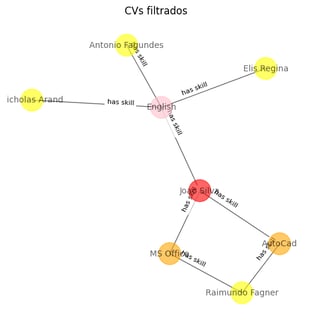
Agora temos que temos uma base de conhecimento estruturada, podemos utilizá-la da forma que desejarmos para tomada de deciões. Suponhamos que, por exemplo, buscamos candidatos que falam inglês e que conheçam AutoCAD e MS Office. Basta aplicar um simples filtro ao nosso grapho que temos as seguites visualizações:

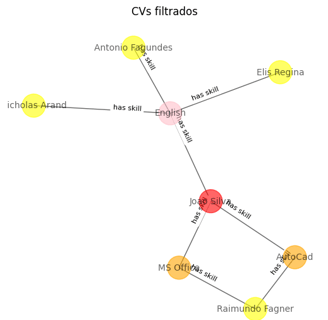
Podemos ver, muito facilmente, quais os candidatos que satisfazem a alguns dos critérios e qual o único candidato que satisfaz a todos.
Este é um exemplo simples usando uma ontologia simples, mas poderíamos muito bem adicionar nesta mesma base de conhecimento as descrições de cargo documentadas da empresa com os conjuntos de habilidades e requisitos que as compõe. Desta forma, para cada currículo que entrasse em nossa base, poderíamos, automaticamente, identificar correspondências com as funções da organização e eventuais vagas abertas.
No próximo post desta série, agora sim, vamos adicionar mais uma camada de IA que vai utilizar um modelo de linguagem para fazerconsultas a esta base que criamos para, por exemplo, responder perguntas sobre nossos candidos usando linguagem natural.
Para quem se interessar, o notebook completo usado nesta demonstração está no meu github: https://github.com/nikinuk/KnowledgeGraphsDemo como "publication II.ipynb"
CVs vêm nos mais diferentes formatos e idiomas